The libferris virtual filesystem gains another tentacle, this time being able to mount mediawiki sites. Some cool use cases right off the cuff:
To read a wiki page
$ fcat wiki://$server/mediawiki/index.php/SamplePage
To write to a wiki page:
$ date | ferris-redirect -T wiki://$server/mediawiki/index.php/Sampler22
For those who are unfamiliar, ferris-redirect takes its stdin and writes it to the file you name. The -T truncates the file first. So the above is sort of like " >| " from bash but you get to write from any application to any libferris filesystem without using FUSE.
To plomp an image up on mediawiki:
ferriscp -av /tmp/Apple.png wiki://$server/mediawiki/index.php/
Which is then available as:
http://$server/mediawiki/index.php/File:Apple.png
And perhaps the coolest little trick so far, which doesn't rely on FUSE or mounting and uses an unmodified vi binary:
$ fedit wiki://alkid/mediawiki/index.php/Sampler22
... modify the "file" ...
ZZ to write it back to the web.
Also, I have tramp hacks to allow this to work from emacs.
Of course, this all interacts with other things libferris can mount, so you can "cp" from your scanner or webcam right to a wiki page or grab text from a wiki and create a pdf or print it out directly.
Oh, and there are Fedora 16 packages now too on openSUSE build service. Just run the following to get it all onto your system.
# yum install libferris-suite
Tuesday, November 22, 2011
Wednesday, October 12, 2011
Semantic Revolutions
I thought a fun little scenario for RDF in ODF would be to bounce information from Evolution, through abiword, to calligra, and then drag it back into evolution again. So information goes from ical to RDF, crosses the clipboard as RDF inside of an ODF file with linked text, and then is dragged back into ical format again. I notice a little timezone bug in there, but on the whole things work as one would expect.
Tuesday, September 20, 2011
Copy and Paste with Semantics...
Copy and Paste now preserves RDF between both Calligra and abiword in both directions. This lets you select some text in a document in either application, copy it, and paste it into the other application and have the RDF that is associated with that part of the document go along with the text you selected.
In the below screencast, the document that Calligra is editing has some contact and event information stored in RDF. The three people in the first sentence all have contact information associated. As you can see, the RDF sidepanel in Calligra lets you know about this as the cursor moves around. James has his phone number captured in RDF which the edit dialog shows. If I select one or more of these contacts and "Copy" them to the clipboard, Calligra creates an ODF file with embedded RDF in it and offers that on the clipboard.
Abiword is happy to accept that ODF content and when you paste it into a document you can see that the RDF links are preserved, and that there are 7 RDF triples associated with James. Of course, you want full disclosure of this information, so clicking show RDF lets you examine and edit those RDF triples.
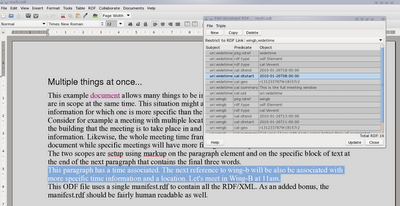
I put a little trick in going the other way just to spice things up a little bit. The multi.odt file that I have open in abiword has two RDF links in scope at the Wing-B link. RDF is associated with the whole paragraph and explicitly with the link itself. In particular, the uri:widetime is associated with the paragraph while the uri:wingb is associated with the RDF link itself. Once I grab that RDF link and copy it to the clipboard, again an ODF file is offered (as well as text and rtf), and again Calligra is more than happy to accept an ODF file on the clipboard. Notice that when I show all the RDF in Calligra both the widetime and wingb RDF triples have now become part of the document.
I made some changes in both calligra and abiword to get this to happen. Changes to the former were quite small. You'll have to grab trunk from both applications if you want to play along at home. The code is committed in both trees.
In the below screencast, the document that Calligra is editing has some contact and event information stored in RDF. The three people in the first sentence all have contact information associated. As you can see, the RDF sidepanel in Calligra lets you know about this as the cursor moves around. James has his phone number captured in RDF which the edit dialog shows. If I select one or more of these contacts and "Copy" them to the clipboard, Calligra creates an ODF file with embedded RDF in it and offers that on the clipboard.
Abiword is happy to accept that ODF content and when you paste it into a document you can see that the RDF links are preserved, and that there are 7 RDF triples associated with James. Of course, you want full disclosure of this information, so clicking show RDF lets you examine and edit those RDF triples.
Copy and Paste of RDF from Calligra to Abiword from Ben Martin on Vimeo.
I put a little trick in going the other way just to spice things up a little bit. The multi.odt file that I have open in abiword has two RDF links in scope at the Wing-B link. RDF is associated with the whole paragraph and explicitly with the link itself. In particular, the uri:widetime is associated with the paragraph while the uri:wingb is associated with the RDF link itself. Once I grab that RDF link and copy it to the clipboard, again an ODF file is offered (as well as text and rtf), and again Calligra is more than happy to accept an ODF file on the clipboard. Notice that when I show all the RDF in Calligra both the widetime and wingb RDF triples have now become part of the document.
Copy and Paste from Abiword to Calligra from Ben Martin on Vimeo.
I made some changes in both calligra and abiword to get this to happen. Changes to the former were quite small. You'll have to grab trunk from both applications if you want to play along at home. The code is committed in both trees.
Tuesday, September 13, 2011
Bringing back /dev/pcm
Taking a peek in /dev/snd one might find device files for their sound card(s). Sequencers, Timers, midi, and pcm device files. I thought it might be interesting to apply a modern face lift to these devices; so now libferrris can mount pulseaudio and has write support for gstreamer.
What this means is you can write "audio" data to a virtual filesystem and have it play that back for you:
$ cat /tmp/sample.flac | ferris-redirect -T gstreamer://output/audio
ferris-redirect is like the shell pipe character but allows direct access to libferris filesystems without mount commands. The -T truncates, so it is like a ">|" bash redirection.
I also plan to make these output directories special. If you write to them like they are a file as in the above then it puts your data there. If you create a subfile and write to it you will be essentially writing to the output file itself. With that you could "cp" a directory of audio files to gstreamer://output/audio and they will play one at a time until you have copied them all to your speakers ;)
$ ferriscp -av /tmp/bongos-dir gstreamer://output/audio
Pulseaudio is available at pulseaudio:// or the shortcut pa://. The tree currently allows you to mute and alter the volume for playing streams and whole output devices. Reading a volume file will tell you the percentage that channel outputs at (or the average for volume-all). Writing a float to the volume files changes the volume to suit your request. The mute files similarly show if the audio is muted and allow you to set that by writing 1 or 0 to the file.
$ fls -0 pa://output/default
mute 0
volume-0 0.729996
volume-1 0.729996
volume-2 0.729996
volume-3 0.729996
volume-4 0.729996
volume-5 0.729996
volume-all 0.729996
$ echo 0.7 | ferris-redirect -T \
"pulseaudio://streams/amarok/Audio Stream/volume-all"
All this ferris-redirect stuff can have it's additional typing mitigated using a suitable inputrc.
For example:
$ cat ~/.inputrc
$include /etc/inputrc
">>>": "| ferris-redirect "
">>|": "| ferris-redirect -T "
This will be in the next libferris release tarball. Things slowly get closer for the libferris QML mobile audio app. You can already do index and search with libferris and get at the results as a QModel for use in QML, now you can also set volumes and "copy" sound to the earphones.
What this means is you can write "audio" data to a virtual filesystem and have it play that back for you:
$ cat /tmp/sample.flac | ferris-redirect -T gstreamer://output/audio
ferris-redirect is like the shell pipe character but allows direct access to libferris filesystems without mount commands. The -T truncates, so it is like a ">|" bash redirection.
I also plan to make these output directories special. If you write to them like they are a file as in the above then it puts your data there. If you create a subfile and write to it you will be essentially writing to the output file itself. With that you could "cp" a directory of audio files to gstreamer://output/audio and they will play one at a time until you have copied them all to your speakers ;)
$ ferriscp -av /tmp/bongos-dir gstreamer://output/audio
Pulseaudio is available at pulseaudio:// or the shortcut pa://. The tree currently allows you to mute and alter the volume for playing streams and whole output devices. Reading a volume file will tell you the percentage that channel outputs at (or the average for volume-all). Writing a float to the volume files changes the volume to suit your request. The mute files similarly show if the audio is muted and allow you to set that by writing 1 or 0 to the file.
$ fls -0 pa://output/default
mute 0
volume-0 0.729996
volume-1 0.729996
volume-2 0.729996
volume-3 0.729996
volume-4 0.729996
volume-5 0.729996
volume-all 0.729996
$ echo 0.7 | ferris-redirect -T \
"pulseaudio://streams/amarok/Audio Stream/volume-all"
All this ferris-redirect stuff can have it's additional typing mitigated using a suitable inputrc.
For example:
$ cat ~/.inputrc
$include /etc/inputrc
">>>": "| ferris-redirect "
">>|": "| ferris-redirect -T "
This will be in the next libferris release tarball. Things slowly get closer for the libferris QML mobile audio app. You can already do index and search with libferris and get at the results as a QModel for use in QML, now you can also set volumes and "copy" sound to the earphones.
Thursday, September 1, 2011
Abiword RDF Drag and Drop
Now that abiword has low level RDF support I thought I'd make it simpler to get some data into the document's RDF. The initial support lets you drag contact and calendar entries from Evolution into your document as shown below. Notice that a new RDF Link is created for you and when you choose to right click that link and "Show RDF" there are many RDF triples that have been created by the D&D action.
I think these sort of user interface additions help to make using RDF quick and easy, even for those who don't know or care what it is and where it gets stored in the document. Abiword can load and save RDF in both it's native abw files and ODF formats. You can of course convert between both without loosing the RDF ;)
I plan to add D&D in the other direction later on, so you can pickup a person from a document or an event. Similar to how many email clients let you import ics calendar files into your local Calendar. Having RDF in ODF lets you share content, style, and semantics, all in a truly open format single file.
Oh, and the code should hit svn trunk real soon now.
Abiword RDF Drag and Drop from Ben Martin on Vimeo.
I think these sort of user interface additions help to make using RDF quick and easy, even for those who don't know or care what it is and where it gets stored in the document. Abiword can load and save RDF in both it's native abw files and ODF formats. You can of course convert between both without loosing the RDF ;)
I plan to add D&D in the other direction later on, so you can pickup a person from a document or an event. Similar to how many email clients let you import ics calendar files into your local Calendar. Having RDF in ODF lets you share content, style, and semantics, all in a truly open format single file.
Oh, and the code should hit svn trunk real soon now.
Thursday, August 18, 2011
RDF Low Level Interaction in Abiword
I've recently mentioned creating and jumping to the RDF Links (xml:id to RDF bridging) in Abiword. I also had a work in progress dialog to allow SPARQL Query execution. Things are moving along quite nicely and the RDF subsystem continues to get stronger with a Triple Editor and updates to the SPARQL dialog shown below and execution support.
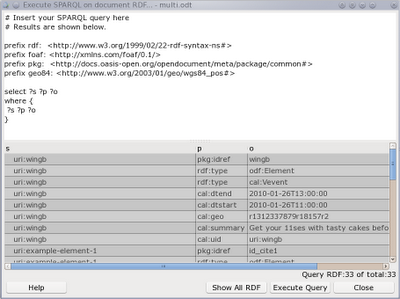
Shown below is the new RDF Editor dialog. The file menu allows you to import and export RDF/XML files into the document. The Triple menu has the same actions as the toolbar; new, copy, and delete. Shown at the bottom of the dialog is the total number of RDF triples for this document. Clicking on a cell in the table lets you edit it and you can use the existing URI prefixes if you like, for example rdf:type instead of the full URI. I have to allow configuration of those prefixes yet.
 When you select some text in Abiword you can use Insert/RDF Link to create a new RDF link for that text. This is much like making a bookmark, hyperlink and other items.
When you select some text in Abiword you can use Insert/RDF Link to create a new RDF link for that text. This is much like making a bookmark, hyperlink and other items.
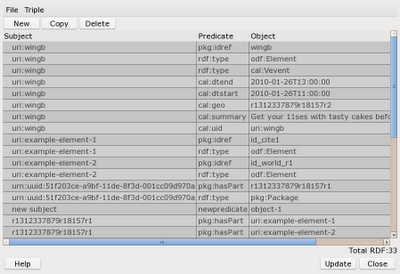
The context menu for an RDF link allows you to edit the RDF associated with link. That window is shown below. There can be many RDF links in scope at any location in the document. Consider the case where a paragraph has RDF linked to it and a sentence and word does too. So when you bring up the RDF editor window from the context menu of an RDF link you get a combo box letting you select which links you want to see the RDF associated with.
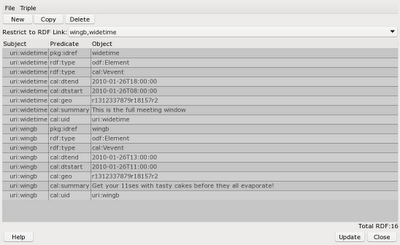
By default the editor shows you all the RDF Links that are in scope where the cursor was located when you opened the dialog from the context menu. In this case widetime is an RDF link for the whole paragraph and wingb is for three words at the end of the paragraph. The dialog shows you the triples that link the subjects to this location: those with ?subject pkg:idref widetime. Selecting a different RDF link from the combo box restricts the triples shown to be only those associated with the RDF link you have chosen.
 I decided to make the dialog automatically link any new triples you create or edit to the RDF link you have specified in the combo box. If there is more than one RDF link shown then the first link is used for new and updated triples.
I decided to make the dialog automatically link any new triples you create or edit to the RDF link you have specified in the combo box. If there is more than one RDF link shown then the first link is used for new and updated triples.
This allows you to select some text, create an RDF link, right click the link and "Show RDF" from the context menu and start adding and editing triples and Abiword will automatically associate all those shown with the RDF link you have selected. Yay, full, low level RDF support with a GUI ;)
In case you have forgotten the scope of an RDF link in the document, the RDF editor will select the scope in the main document when you select a triple in the editor. I might make that functionality have a toggle button in the toolbar instead of making it happen automatically all the time.
One of the plugins that comes with Abiword is the "AbiCommand" which gives you a console interface to Abiword. You can start it from the shell using:
$ abiword --plugin AbiCommand
...
AbiWord command line plugin: Type "quit" to exit
AbiWord:>
I have added some new RDF commands to the AbiCommand plugin which allows fairly good interaction with RDF from the command line. The context-model commands allow you to set and interact with a submodel of all the RDF in the document. For example, only the RDF that is associated with a given xml:id. All updates to RDF happen via a mutation object. So you first use rdf-mutation-create, then add/remove as desired and complete things with rdf-mutation-commit. For those who are still reading now, see pd_DocumentRDF.h in the C++ source code and you'll notice createMutation() in the model, with add(), remove(), commit() and rollback() methods. The new commands in AbiCommand are shown below:
Some examples of AbiCommand interaction are shown below to give a little idea of use. These are using the multi.odt from my plugtest github repository.

{kind=link}
Shown below is the new RDF Editor dialog. The file menu allows you to import and export RDF/XML files into the document. The Triple menu has the same actions as the toolbar; new, copy, and delete. Shown at the bottom of the dialog is the total number of RDF triples for this document. Clicking on a cell in the table lets you edit it and you can use the existing URI prefixes if you like, for example rdf:type instead of the full URI. I have to allow configuration of those prefixes yet.
 When you select some text in Abiword you can use Insert/RDF Link to create a new RDF link for that text. This is much like making a bookmark, hyperlink and other items.
When you select some text in Abiword you can use Insert/RDF Link to create a new RDF link for that text. This is much like making a bookmark, hyperlink and other items.
The context menu for an RDF link allows you to edit the RDF associated with link. That window is shown below. There can be many RDF links in scope at any location in the document. Consider the case where a paragraph has RDF linked to it and a sentence and word does too. So when you bring up the RDF editor window from the context menu of an RDF link you get a combo box letting you select which links you want to see the RDF associated with.
By default the editor shows you all the RDF Links that are in scope where the cursor was located when you opened the dialog from the context menu. In this case widetime is an RDF link for the whole paragraph and wingb is for three words at the end of the paragraph. The dialog shows you the triples that link the subjects to this location: those with ?subject pkg:idref widetime. Selecting a different RDF link from the combo box restricts the triples shown to be only those associated with the RDF link you have chosen.
 I decided to make the dialog automatically link any new triples you create or edit to the RDF link you have specified in the combo box. If there is more than one RDF link shown then the first link is used for new and updated triples.
I decided to make the dialog automatically link any new triples you create or edit to the RDF link you have specified in the combo box. If there is more than one RDF link shown then the first link is used for new and updated triples.
This allows you to select some text, create an RDF link, right click the link and "Show RDF" from the context menu and start adding and editing triples and Abiword will automatically associate all those shown with the RDF link you have selected. Yay, full, low level RDF support with a GUI ;)
In case you have forgotten the scope of an RDF link in the document, the RDF editor will select the scope in the main document when you select a triple in the editor. I might make that functionality have a toggle button in the toolbar instead of making it happen automatically all the time.

One of the plugins that comes with Abiword is the "AbiCommand" which gives you a console interface to Abiword. You can start it from the shell using:
$ abiword --plugin AbiCommand
...
AbiWord command line plugin: Type "quit" to exit
AbiWord:>
I have added some new RDF commands to the AbiCommand plugin which allows fairly good interaction with RDF from the command line. The context-model commands allow you to set and interact with a submodel of all the RDF in the document. For example, only the RDF that is associated with a given xml:id. All updates to RDF happen via a mutation object. So you first use rdf-mutation-create, then add/remove as desired and complete things with rdf-mutation-commit. For those who are still reading now, see pd_DocumentRDF.h in the C++ source code and you'll notice createMutation() in the model, with add(), remove(), commit() and rollback() methods. The new commands in AbiCommand are shown below:
...RDF subsystem...
Where a function reads RDF, it will try to use the RDF context model if it is set
Otherwise the entire RDF for the document is used.
An RDF context is obtained using rdf-set-context*
and cleared with rdf-clear-context-model
rdf-import <src> - load all RDF from an RDF/XML file at <src> into the document
rdf-export <dst> - save all document RDF to an RDF/XML file at <dst>
rdf-clear-context-model - RDF can at times use a context model which is a subset of
all the RDF associated with the document.
This command clears that and uses all the RDF again.
rdf-set-context-model-pos <pos> - Use a context model with the subset of RDF
associated with the given document position
rdf-set-context-model-xmlid <xmlid> [readxmlid1,readxmlid2]
- Use a context model with the subset of RDF
associated with the given document xml:id value
rdf-context-show-objects <s> <p> - Show the object list for the given subject,predicate pair
rdf-context-show-subjects <p> <o> - Show the subject list for the given predicate,object pair
rdf-context-contains <s> <p> <o> - True if the triple is there.
rdf-context-show-arcs-out <s> - Show the predicate objects associated
with the given subject
rdf-get-xmlids - Get a comma separated list of the xml:ids assocaited
with the current cursor location
rdf-get-all-xmlids - Get a comma separated list of all the xml:ids
rdf-get-xmlid-range <xmlid> - Show the start and end document position associated
with the given <xmlid>
rdf-movept-xmlid-start <xmlid> - Move the cursor location to the start of the range
for the given xml:id value
rdf-movept-xmlid-end <xmlid> - Move the cursor location to the end of the range
for the given xml:id value
rdf-uri-to-prefixed <uri> - Convert full uri to prefix:rest
rdf-prefixed-to-uri <uri> - Convert prefix:rest to full uri
rdf-size - Number of RDF triples for context
rdf-mutation-create - Start a RDF mutation for the document
rdf-mutation-add <s> <p> <o>- Add the given triple to the current mutation
rdf-mutation-remove <s> <p> <o>- Remove the given triple in the current mutation
rdf-mutation-commit - Commit current RDF mutation to the document
rdf-mutation-rollback - Throw away changes in current RDF mutation
rdf-execute-sparql - Execute SPARQL query against RDF context
rdf-xmlid-insert <xmlid> - Insert xml:id for current selection
rdf-xmlid-delete <xmlid> - Delete the xml:id from the document
Some examples of AbiCommand interaction are shown below to give a little idea of use. These are using the multi.odt from my plugtest github repository.
load /tmp/multi.odt
rdf-export /tmp/output.rdf
rdf-import /tmp/extra.rdf
rdf-set-context-model-pos 1006
rdf-export /tmp/1006.rdf
rdf-set-context-model-xmlid wingb
rdf-export /tmp/wingb.rdf
rdf-clear-context-model
rdf-export /tmp/all.rdf
rdf-get-xmlid-range wingb
rdf-execute-sparql "prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix foaf: <http://xmlns.com/foaf/0.1/>
prefix pkg: <http://docs.oasis-open.org/opendocument/meta/package/common#>
prefix geo84: <http://www.w3.org/2003/01/geo/wgs84_pos#>
select ?s ?p ?o ?rdflink
where {
?s ?p ?o .
?s pkg:idref ?rdflink .
filter( str(?rdflink) = \"wingb\" || str(?rdflink) = \"widetime\" )
}"
load /tmp/multi.odt
movept +27
selectstart
movept +4
rdf-xmlid-insert foo
save /tmp/updated.odt
load /tmp/multi.odt
rdf-context-contains uri:wingb rdf:type http://www.w3.org/2002/12/cal/icaltzd#Vevent
rdf-context-show-objects uri:wingb rdf:type
rdf-context-show-subjects rdf:type http://www.w3.org/2002/12/cal/icaltzd#Vevent
rdf-context-show-arcs-out uri:wingb
Tuesday, August 2, 2011
RDF Linking in Abiword
Another minor step forward in the quest to make the RDF facility in ODF more useful to document authors... Abiword can now create links to RDF and you can jump to these links in a similar manner to how bookmarks work. The upside to using RDF links over bookmarks is that you can associate meaning with the RDF links. So for example, the text "Barry" can be associated with his vcard and possibly normal work geolocation.
Making a new RDF link is just like inserting a bookmark:
 And the "Go To..." dialog now offers RDF links as first class citizens. I did a little tweaking to this goto window while I was at it; moving things into a paged configuration and abstracting out some common code into utility functions.
And the "Go To..." dialog now offers RDF links as first class citizens. I did a little tweaking to this goto window while I was at it; moving things into a paged configuration and abstracting out some common code into utility functions.
 On the API front, there are now STL like iterators for the RDF and that theme will be present in the query results engine and perhaps also in the arcsOut() API. Speaking of querying, the window for SPARQL is coming along. I'll start working on the actual query execution shortly. Notice that the RDF triples are shown with namespaces in effect so you get something more readable.
On the API front, there are now STL like iterators for the RDF and that theme will be present in the query results engine and perhaps also in the arcsOut() API. Speaking of querying, the window for SPARQL is coming along. I'll start working on the actual query execution shortly. Notice that the RDF triples are shown with namespaces in effect so you get something more readable.
 As I mentioned in my previous post, the purple links can be turned on and off to highlight parts of the document with RDF associated. Using a special menu item you can pull up the SPARQL query dialog with a preformed query to show just the RDF associated with the current cursor location.
As I mentioned in my previous post, the purple links can be turned on and off to highlight parts of the document with RDF associated. Using a special menu item you can pull up the SPARQL query dialog with a preformed query to show just the RDF associated with the current cursor location.
I admit that some of this is quite low level, for example directly inspecting the triples for the cursor position. But full disclosure isn't a bad thing right? I syndicated this to planet KDE because Calligra handles RDF too. Hopefully posts about RDF are interesting to hackers regardless of the desktop platform :)
Making a new RDF link is just like inserting a bookmark:
 And the "Go To..." dialog now offers RDF links as first class citizens. I did a little tweaking to this goto window while I was at it; moving things into a paged configuration and abstracting out some common code into utility functions.
And the "Go To..." dialog now offers RDF links as first class citizens. I did a little tweaking to this goto window while I was at it; moving things into a paged configuration and abstracting out some common code into utility functions. On the API front, there are now STL like iterators for the RDF and that theme will be present in the query results engine and perhaps also in the arcsOut() API. Speaking of querying, the window for SPARQL is coming along. I'll start working on the actual query execution shortly. Notice that the RDF triples are shown with namespaces in effect so you get something more readable.
On the API front, there are now STL like iterators for the RDF and that theme will be present in the query results engine and perhaps also in the arcsOut() API. Speaking of querying, the window for SPARQL is coming along. I'll start working on the actual query execution shortly. Notice that the RDF triples are shown with namespaces in effect so you get something more readable. As I mentioned in my previous post, the purple links can be turned on and off to highlight parts of the document with RDF associated. Using a special menu item you can pull up the SPARQL query dialog with a preformed query to show just the RDF associated with the current cursor location.
As I mentioned in my previous post, the purple links can be turned on and off to highlight parts of the document with RDF associated. Using a special menu item you can pull up the SPARQL query dialog with a preformed query to show just the RDF associated with the current cursor location.I admit that some of this is quite low level, for example directly inspecting the triples for the cursor position. But full disclosure isn't a bad thing right? I syndicated this to planet KDE because Calligra handles RDF too. Hopefully posts about RDF are interesting to hackers regardless of the desktop platform :)
Tuesday, July 19, 2011
Abiword & RDF Gusto
I recently blogged about updating Calligra to improve its RDF support and bring back support for viewing and editing location information using Marble. A computer loves RDF because it is nice and verbose and allows low level unambiguous expression of semantics in a format that a machine can work with. For a human however, some might find having long descriptors, schemas and the like just to say "meet me at the Mall" a little tedious. One of the many challenges that I see for office applications wanting to offer RDF to the user is making it visible in a subtle way.
Abiword can now colour code parts of the document which have RDF associated with them and tell you how that association is formed, and how much RDF is linked at any point. In the below, the purple text has some RDF associated, and the purple "Mark" I have the mouse pointer on so it shows the bubble text letting you know how the RDF is attached and how much of it there is.
 In the future I of course want to let you know more; is the RDF location, contact, event, or related to another domain. It would also be nice to highlight RDF only for types. So, for example if you are interested only in the times that trains leave then highlight departure logistics in bold red. The computer knows what you mean too, so might also want to offer a menu button to check if the train is on time or not.
In the future I of course want to let you know more; is the RDF location, contact, event, or related to another domain. It would also be nice to highlight RDF only for types. So, for example if you are interested only in the times that trains leave then highlight departure logistics in bold red. The computer knows what you mean too, so might also want to offer a menu button to check if the train is on time or not.
Being able to highlight like this is a good start because it allows users who are unfamiliar with the document the chance to know exactly where there might be RDF "hiding".
Abiword can now colour code parts of the document which have RDF associated with them and tell you how that association is formed, and how much RDF is linked at any point. In the below, the purple text has some RDF associated, and the purple "Mark" I have the mouse pointer on so it shows the bubble text letting you know how the RDF is attached and how much of it there is.
 In the future I of course want to let you know more; is the RDF location, contact, event, or related to another domain. It would also be nice to highlight RDF only for types. So, for example if you are interested only in the times that trains leave then highlight departure logistics in bold red. The computer knows what you mean too, so might also want to offer a menu button to check if the train is on time or not.
In the future I of course want to let you know more; is the RDF location, contact, event, or related to another domain. It would also be nice to highlight RDF only for types. So, for example if you are interested only in the times that trains leave then highlight departure logistics in bold red. The computer knows what you mean too, so might also want to offer a menu button to check if the train is on time or not.Being able to highlight like this is a good start because it allows users who are unfamiliar with the document the chance to know exactly where there might be RDF "hiding".
Friday, July 15, 2011
Calligra & RDF Smaak
As some readers will already know, the ODF document standard has support for including one or more RDF/XML files. I have made a few such files, and will grow that collection over time. The weekend hike document cites a few people, links some to a location and also cites a time and place. While one could just say "Dom Plein" or "11 am Wednesday" these purely text references are subjective and require a human to read them.
On the other hand, the location could have an exact bounding polygon or point with digital longitude and latitude information. A computer is all to happy to use that precise description to offer maps and "how to get there from here" type information. And the 11am is of course dubious because it doesn't link to a timezone, a human will know we are not talking UK time or the ACDT timezone. But that requires inference from the cited location and knowledge of which Plein that is, or rather, which timezone that Plein is in.
I did a little hacking to freshen up some of the RDF code in Calligra and bring back optional support for using Marble to show and edit location information. The below is the weekend hike example from the github above. James, Joyce, and Mark all have contact RDF associated, with Mark also giving his location. The "next weekend" at the end of the first paragraph has both a time and place associated. In the screenshot I've opened up the place to edit it. Rather simple to drag a map around and click OK than to know the digital coordinates right of the top of your head ;)

I was hacking on fixing the same bug as boemann on #calligra, which is strange for me as I normally don't overlap on things. It seems along the way setCanvas() was called again so I removed my explicit view passing stuff in the update I just git pushed. It looks like the docker was fixed correctly by somebody else in the end. My SPARQL updates should still help. It has been a while since I hacked on this codebase, and I have to thank the Calligra guys for being so welcoming and having such a fun contribution environment! I'm fortunate to be able to hack on two projects, Abiword and Calligra, which are both so welcoming :)
On the other hand, the location could have an exact bounding polygon or point with digital longitude and latitude information. A computer is all to happy to use that precise description to offer maps and "how to get there from here" type information. And the 11am is of course dubious because it doesn't link to a timezone, a human will know we are not talking UK time or the ACDT timezone. But that requires inference from the cited location and knowledge of which Plein that is, or rather, which timezone that Plein is in.
I did a little hacking to freshen up some of the RDF code in Calligra and bring back optional support for using Marble to show and edit location information. The below is the weekend hike example from the github above. James, Joyce, and Mark all have contact RDF associated, with Mark also giving his location. The "next weekend" at the end of the first paragraph has both a time and place associated. In the screenshot I've opened up the place to edit it. Rather simple to drag a map around and click OK than to know the digital coordinates right of the top of your head ;)

I was hacking on fixing the same bug as boemann on #calligra, which is strange for me as I normally don't overlap on things. It seems along the way setCanvas() was called again so I removed my explicit view passing stuff in the update I just git pushed. It looks like the docker was fixed correctly by somebody else in the end. My SPARQL updates should still help. It has been a while since I hacked on this codebase, and I have to thank the Calligra guys for being so welcoming and having such a fun contribution environment! I'm fortunate to be able to hack on two projects, Abiword and Calligra, which are both so welcoming :)
Monday, July 11, 2011
RDF in ODF: Abiword & Calligra
RDF has been slowly making it's way into Office applications. The ODF standard includes support for shipping RDF/XML file(s) inside the zip file that is an odt file. This RDF can also be linked to particular part(s) of the document text so that you and your computer both know where the RDF is most relevant. For example, if "Fred" in the document has his phone number, location, and cake preference in RDF, that can all be linked just to the four characters "Fred" so that it all makes sense. Strange as it might be, not everybody likes Baumkuchen, and it is fairly likely not to be relevant to a stock quote in another part of the document.
RDF has spread to OpenOffice, abiword, KOffice, and Calligra. All of these applications can read and write RDF in text documents. The later two also include a GUI to allow you to query, inspect, and update the RDF. Since I'm hacking on abiword, I've been throwing around how to best expose RDF to the person using abiword for document editing...
First, this is what Calligra does. The main document window includes an RDF docker which shows you the high level "Semantic objects". These are things which make use of many RDF triples to present a single object type such as a contact, calendar event, location, or explicit train trip. Note that the RDF docker only shows you the semantic objects for the RDF which is relevant to the current document cursor position.
 The Document Information window also lets you get at all of the RDF which ships with an ODF file. The Semantic tab is very similar to the RDF docker but shows all the Semantic Objects regardless of where they are relevant in the document (if at all). As you can see below, editing the "Dan" person semantic object you can set their name, nickname, phone number, and homepage. Of course, more information is relevant to people and this whole section should be expanded to cater for that. And yes, for Calligra having a good hookup to Akonadi would be of great use for all.
The Document Information window also lets you get at all of the RDF which ships with an ODF file. The Semantic tab is very similar to the RDF docker but shows all the Semantic Objects regardless of where they are relevant in the document (if at all). As you can see below, editing the "Dan" person semantic object you can set their name, nickname, phone number, and homepage. Of course, more information is relevant to people and this whole section should be expanded to cater for that. And yes, for Calligra having a good hookup to Akonadi would be of great use for all. Contacts use the FOAF RDF schema in Calligra. This allows not only contact information but also the relations between contacts to be expressed. FOAF is about Friends of a Friend after all. Looking at the above you might think name, phone etc are each going to be a triple in the RDF from the document. The triples tab lets you get at that lower level RDF goodness as shown below. A few things to note; while RDF is triples, each object has a type (is it a chunk of text or a link to another subject), and since there are many possible "files" the RDF/XML came from that is tracked for each triple so they can go back there too on save.
Contacts use the FOAF RDF schema in Calligra. This allows not only contact information but also the relations between contacts to be expressed. FOAF is about Friends of a Friend after all. Looking at the above you might think name, phone etc are each going to be a triple in the RDF from the document. The triples tab lets you get at that lower level RDF goodness as shown below. A few things to note; while RDF is triples, each object has a type (is it a chunk of text or a link to another subject), and since there are many possible "files" the RDF/XML came from that is tracked for each triple so they can go back there too on save.
Notice in the above that prefixes are included in the subject, predicate, and object columns. This is an attempt to make the raw RDF less verbose and somewhat simpler to handle. The namespaces tab lets you set these up. Any namespaces that are used in the RDF/XML from the ODF file are automatically added and used for you.
The stylesheets tab I'll cover at another time. The SPARQL tab lets you run a query against all the RDF for the document. The one I've run here is the default one that Calligra shows you, which will select all the triples from the document without restriction. The subject, predicate, and object resulting are shown in the bottom half of the window.

I was thinking about all of this recently because I'm now looking to add GUI stuff to abiword to allow RDF interaction. The first idea was to simply add a "edit RDF" context menu item to allow you to associate one or more triples with the cursor position or current selection. The ability to define and reuse namespaces would also help to make such a dialog less painful to use. This brings the design close to the combined "Triples" and "Namespaces" tabs of the Calligra Document Information window. This might be OK for determined users who already really, really know they want to do these things. But I tend to think there are more folks who could take advantage of using RDF but not necessarily care about it.
Simplicity for users was the driving force behind the design of Semantic Objects and the use of Drag and Drop to and from other applications to create and harvest RDF data. I think it is much simpler to grab the "Fred" contact from Evolution and drop it into the document than to work out that you want to use FOAF and the exact predicates to create a well defined RDF graph for the Fred contact and then copy and paste each of those pieces of data individually.
One might like to consider the Triples+Namespaces as a special type of Semantic Object, a "raw" object if you will. This brings together the design of the advanced and user friendly interaction into a single dialog. As the namespaces are likely to have whole document scope they can be setup and edited elsewhere. Unfortunately I had a bit of trouble working out how to populate a tree or list in glade-2 or glade-3 for mock ups, so these are gimped a bit too.
The dialog below is a semantic object editor with the advanced tab allowing raw interaction. As there can be zero or more semantic objects of a given type in scope at any point there is a list on the left side allowing you to choose which object of a type to view. Perhaps that should be a drop down list at the top of the tab to save screen space.
 The email and VoIP links should start a new message or request a phone call with the person respectively. Such actions should also be available without getting to the editor itself. My current plan is to have the advanced tab allow interaction with the raw triples. Remember though that triples carry type information, possibly extra context, and/or perhaps a range of the revisions in a change tracked document that the triple is valid for. So its by no means just a list with three columns as the name triples might at first imply.
The email and VoIP links should start a new message or request a phone call with the person respectively. Such actions should also be available without getting to the editor itself. My current plan is to have the advanced tab allow interaction with the raw triples. Remember though that triples carry type information, possibly extra context, and/or perhaps a range of the revisions in a change tracked document that the triple is valid for. So its by no means just a list with three columns as the name triples might at first imply.A somewhat problematic first blush at this gives the below. I'm thinking that the subj, pred, and object strings can be namespace:foo strings, possibly with some completion for known namespaces like foaf, et al. The type is fairly OK as these are fixed and mainly URI or Object.

The revision range selection is a real challenge. This might become some sort of date range bar line the timeline or timeplot from the simile widgets. The trick as is usual is extrapolating the extra dimension from what is in it's vanilla sense a linear one dimensional data set ( time, revision ). Though having the revisions and their descriptions in the top half of the timeline and the ability to pan and zoom seeing a density plot in the lower half would work for starters.

I'm thinking that as well as showing you all the triples that maybe allowing simple one or two line SPARQL to be run to find the triples to edit would be preferable. Perhaps it doesn't add much for a small document range with only 20 triples associated, but to use the dialog on the whole document too, you might want to limit triples to "current revision" and foaf related only for example. Using a triple list allows you to sort by column and search, but such a search could also be performed with relatively simple SPARQL. And normally, and extremely unfortunately, one normally doesn't get to stable sort lists by 2+ columns. A limitation I try to avoid inflicting.
So in summary, raw triple editing can be just an advanced semantic object. The list of semantic objects should be able to be found from a document position (cursor) or arbitrary begin-end range. The later catering for whole document RDF editing as a special case. For contacts there might be one or more semantic objects for any doc position or range, but there will only be one raw-triple semantic object for any range.
Though I'm still chucking around how to make the query/edit part most convenient for users for the raw triples semantic object.
Saturday, June 18, 2011
Libferris for Fedora 15
My openSUSE Build Service project now has rpm files for Fedora 15 for the libferris chain including gevas and the ego file manager. This includes the recently mentioned updates to postgresql indexing allowing for indexed resolution of some regex queries (2ms query time on 200+k files).
During the updates, I found the normal little things such as gcc being more selective about what it likes to compile and treated these cases. The main glitch I found was in the @F15/../gtk/gtkmain.h header there is a prototype which takes a "GModule *module" argument. This means I had to include gmodule.h before gtk.h to get that type in scope otherwise things failed to compile.
The Fedora 15 packages have support for printing with Qt, so one can echo foo > printer://default/ or "cp" an image to the printer. Scanning support will pop up in a future build once the few tiny changes to ksane I sent in trickle through to the shipped KDE release in Fedora.
Perhaps soon I'll make Phonon available as a filesystem too so one can cp an ogg file to sound://default to play it. Seeking will be interesting, as it's not normally a common case to start copying a file at a given offset. But that smells like a seek during playback to me. I'm looking forward to making a QML audio player, with index-search and playback already filesystems the heavy lifting will have already been done :)
During the updates, I found the normal little things such as gcc being more selective about what it likes to compile and treated these cases. The main glitch I found was in the @F15/../gtk/gtkmain.h header there is a prototype which takes a "GModule *module" argument. This means I had to include gmodule.h before gtk.h to get that type in scope otherwise things failed to compile.
The Fedora 15 packages have support for printing with Qt, so one can echo foo > printer://default/ or "cp" an image to the printer. Scanning support will pop up in a future build once the few tiny changes to ksane I sent in trickle through to the shipped KDE release in Fedora.
Perhaps soon I'll make Phonon available as a filesystem too so one can cp an ogg file to sound://default to play it. Seeking will be interesting, as it's not normally a common case to start copying a file at a given offset. But that smells like a seek during playback to me. I'm looking forward to making a QML audio player, with index-search and playback already filesystems the heavy lifting will have already been done :)
Monday, May 2, 2011
Searching again (400ms -> 2ms)
The problem statement: you want to search for a file using any arbitrary substring contained in the file url. This is deceptively hard, if you think in a relational db way, you want something "like %foo%" where the leading percent will force indexes to be considered redundant and a sequential scan to ensue. If you try instead to break up the file's URL into words and use a full text indexing solution you will find your old friend the leading percent again, like here for Lucene.
One easy way to use full text indexing style and allow substrings is to cheat. First disable word stemming (ie, dont turn diving and dive into a stemmed "dive" word). Then for each word to be added to the full text index, shift it left from 1..10 times. So wonderful, onderful, nderful, derful, erful etc are all added as words for the same URL. This is most simply accomplished using a postgresql function to do the shifting.
Then when you search for a substring foo you want to find to_tsquery('simple,'foo:*') as a fulltext query on your url column. As prefix searches are allowed in fulltext index engines like Lucene and postgresql's TSearch2 engine, this evaluates quite quickly.
For 200,000 URLs when using the raw regex match "~" in postgresql you might see 400ms evaluation times, the same data using a gin index on to_tsvector('simple',fnshiftstring(url)) might return in 2-3ms. Of course the index can't always handle your regular expression, but if you can tease out substrings which must be present from your regular expression, a shifted gin index could drop evaluation times for you. eg, .*[Ff]oob([0-9]... could use a shifted search for "oob" as a prefilter to full regular expression evaluation.
Getting down to a few ms evaluation allows GUIs to return some sample results as you type in your regular expression. This speed up will be available in 1.5.6+ of libferris.
A while ago I released an engine for maemo with statistical spatial indexing for regular expression evaluation. It's an interesting problem IMHO, and its also a very common one.
One easy way to use full text indexing style and allow substrings is to cheat. First disable word stemming (ie, dont turn diving and dive into a stemmed "dive" word). Then for each word to be added to the full text index, shift it left from 1..10 times. So wonderful, onderful, nderful, derful, erful etc are all added as words for the same URL. This is most simply accomplished using a postgresql function to do the shifting.
Then when you search for a substring foo you want to find to_tsquery('simple,'foo:*') as a fulltext query on your url column. As prefix searches are allowed in fulltext index engines like Lucene and postgresql's TSearch2 engine, this evaluates quite quickly.
For 200,000 URLs when using the raw regex match "~" in postgresql you might see 400ms evaluation times, the same data using a gin index on to_tsvector('simple',fnshiftstring(url)) might return in 2-3ms. Of course the index can't always handle your regular expression, but if you can tease out substrings which must be present from your regular expression, a shifted gin index could drop evaluation times for you. eg, .*[Ff]oob([0-9]... could use a shifted search for "oob" as a prefilter to full regular expression evaluation.
Getting down to a few ms evaluation allows GUIs to return some sample results as you type in your regular expression. This speed up will be available in 1.5.6+ of libferris.
A while ago I released an engine for maemo with statistical spatial indexing for regular expression evaluation. It's an interesting problem IMHO, and its also a very common one.
Friday, April 29, 2011
Everything is a file? Spitting it out again...
After recently adding support for scanning through a virtual filesystem interface in libferris I thought I'd complete the cycle and add printer-as-filesystem too. This of course allows the neat trick to "copy" a document from your scanner and dumping it to a printer:
$ ferriscp scanner:///my-scanner/color/scan.png printer:///my-friends-printer/
Naturally the printer and scanner don't have to be in the same room etc. As you can see from the above, writing a picture to a file inside the printer's virtual directory prints that image to paper. By default images are smooth stretched to fit the entire page, not a huge issue if you scan and print at the same DPI.
Images can come from anywhere, to hard copy a webcam
$ ferriscp gstreamer://capture/webcam.jpg printer:///Ich-bin-ein-drucker/
If on the other hand you write a plain text file to the printer's directory it will be printed in an acceptable manner too. So something like this works
$ date | ferris-redirect -T printer://Cups-PDF/foo
In this case, you can expect a ~/Desktop/foo.pdf file which is a PDF document with the current date in it. One can think if ferris-redirect as the shell "|" but which natively knows about all the libferris filesystems. On the other hand, you could use FUSE to mount printer:// at some normal kernel location and just do
$ date >| ~/printer/Cups-PDF/foo
Of course, none of this is meant to replace programs which let you tweak how images are printed, format how text will appear, or select from the myriad of options your printer offers you. But if you want a piece of paper from a scanner to a printer, such a "copy" might be just the ticket.
$ ferriscp scanner:///my-scanner/color/scan.png printer:///my-friends-printer/
Naturally the printer and scanner don't have to be in the same room etc. As you can see from the above, writing a picture to a file inside the printer's virtual directory prints that image to paper. By default images are smooth stretched to fit the entire page, not a huge issue if you scan and print at the same DPI.
Images can come from anywhere, to hard copy a webcam
$ ferriscp gstreamer://capture/webcam.jpg printer:///Ich-bin-ein-drucker/
If on the other hand you write a plain text file to the printer's directory it will be printed in an acceptable manner too. So something like this works
$ date | ferris-redirect -T printer://Cups-PDF/foo
In this case, you can expect a ~/Desktop/foo.pdf file which is a PDF document with the current date in it. One can think if ferris-redirect as the shell "|" but which natively knows about all the libferris filesystems. On the other hand, you could use FUSE to mount printer:// at some normal kernel location and just do
$ date >| ~/printer/Cups-PDF/foo
Of course, none of this is meant to replace programs which let you tweak how images are printed, format how text will appear, or select from the myriad of options your printer offers you. But if you want a piece of paper from a scanner to a printer, such a "copy" might be just the ticket.
Tuesday, April 26, 2011
Blocking a nostril
I have been meaning to add sane support to libferris since I upgraded my scanner to something modern. I now also have an Automatic Document Feeder (ADF) so naturally that needs to be a filesystem too. A quick example of how this might be useful, to turn a document into something on screen quickly:
$ fcat sane:///my-scanner/color/scan.jpg | okular -
The trees under sane:// allow preconfigured scanning units and discovery. If you have setup my-scanner then no device listing is performed with sane, a good thing because discovery can be slow. When you configure a scanner you create one or more directories with specific configurations of how you want the scan to proceed. Incidentally, configuration is of course done with a filesystem. Inside ~/.ferris/sane you create a directory for your scanner, plomp the device name into scanner/device and create directories with scanning options for that scanner.
As well as scan.jpg there is a directory "adf" which chomps new things from the ADF for each file you read. Having this directory allows you to grab 20 documents by a normal looking posix like command such as:
$ ferriscp -av sane:///adf/gray-100/adf /tmp/
in this case, I made two trees, color-N and gray-N which scan in color or grayscale at a given DPI (100,300,600 etc). So I can get most of what I want by picking the right directory. "adf" is a softlink to my scanner (a local link in ~/.ferris/sane from adf to "my-scanner"). Using links like this means I can replace the hardware and scripts can still just ask for "the adf" scanner and get something.
One might wonder what happens for a scanner which is not known to the system. The ".discovery" configuration inside ~/.ferris/sane provides defaults for such devices, so you can have your color/gray DPI directories magically appear for discovered scanners too. Of course, most of the gray directories are similar, so softlinks are your friend except for the "resolution" file which you want to change per directory.
Discovery isn't performed for the above commands, because libferris uses short cut directory loading as it knows explicitly how to make the virtual filesystems for preconfigured scanners.
Some hints on configuration will be in dot-ferris/sane/dot-discovered which will be in libferris 1.5.6+ along with the code to actually make it happen.
$ fcat sane:///my-scanner/color/scan.jpg | okular -
The trees under sane:// allow preconfigured scanning units and discovery. If you have setup my-scanner then no device listing is performed with sane, a good thing because discovery can be slow. When you configure a scanner you create one or more directories with specific configurations of how you want the scan to proceed. Incidentally, configuration is of course done with a filesystem. Inside ~/.ferris/sane you create a directory for your scanner, plomp the device name into scanner/device and create directories with scanning options for that scanner.
As well as scan.jpg there is a directory "adf" which chomps new things from the ADF for each file you read. Having this directory allows you to grab 20 documents by a normal looking posix like command such as:
$ ferriscp -av sane:///adf/gray-100/adf /tmp/
in this case, I made two trees, color-N and gray-N which scan in color or grayscale at a given DPI (100,300,600 etc). So I can get most of what I want by picking the right directory. "adf" is a softlink to my scanner (a local link in ~/.ferris/sane from adf to "my-scanner"). Using links like this means I can replace the hardware and scripts can still just ask for "the adf" scanner and get something.
One might wonder what happens for a scanner which is not known to the system. The ".discovery" configuration inside ~/.ferris/sane provides defaults for such devices, so you can have your color/gray DPI directories magically appear for discovered scanners too. Of course, most of the gray directories are similar, so softlinks are your friend except for the "resolution" file which you want to change per directory.
Discovery isn't performed for the above commands, because libferris uses short cut directory loading as it knows explicitly how to make the virtual filesystems for preconfigured scanners.
Some hints on configuration will be in dot-ferris/sane/dot-discovered which will be in libferris 1.5.6+ along with the code to actually make it happen.
Sunday, April 24, 2011
Change Tracking: Why?
As some of my past posts have mentioned, the OASIS group is currently working out how it wishes to extend support for change tracking in ODF. The change tracking feature allows you to have an office application remember what changes you have made and associate them with one or more revisions. There are many examples where governments might want such traceability, but small businesses are likely to find this functionality valuable too.
Late last year there was an ODF plugfest held in Brussels where it was decided that an Advanced Document Collaboration subcommittee should be formed to work out how to serialize tracked changes into ODF.
There are currently two proposals. One which is generic and tracks how the XML of the ODF is modified over time, and an extension to the limited change tracking that already exists in ODF 1.2.
As my previous posts have mentioned, I'm involved in making abiword able to produce and consume ODF files which contain tracked changes in the format of the generic proposal.
See my github for abiword and its change tracking test suite. Ganesh Paramasivam has been working to make Calligra and KOffice support the generic proposal too, and Jos van den Oever has done some hacking to enrich WebODF for change tracking.
As I have been going along implementing things in abiword, I've been clarifying some points on the oasis office-collab mailing list, and participating in some of the general conversation there too.
Some of the differences between the two proposals can have a large impact to the complexity of implementing change tracking in applications. Folks who are involved in office applications which use ODF might like to read up on the proposals and have their say on the future of this feature before a decision is made for you.
I think it is important for ODT to include a good, complete change tracking specification because it would offer all people the ability to collaborate on documents and businesses the change to know the exact extent of modifications made to documents by each party.
Late last year there was an ODF plugfest held in Brussels where it was decided that an Advanced Document Collaboration subcommittee should be formed to work out how to serialize tracked changes into ODF.
There are currently two proposals. One which is generic and tracks how the XML of the ODF is modified over time, and an extension to the limited change tracking that already exists in ODF 1.2.
As my previous posts have mentioned, I'm involved in making abiword able to produce and consume ODF files which contain tracked changes in the format of the generic proposal.
See my github for abiword and its change tracking test suite. Ganesh Paramasivam has been working to make Calligra and KOffice support the generic proposal too, and Jos van den Oever has done some hacking to enrich WebODF for change tracking.
As I have been going along implementing things in abiword, I've been clarifying some points on the oasis office-collab mailing list, and participating in some of the general conversation there too.
Some of the differences between the two proposals can have a large impact to the complexity of implementing change tracking in applications. Folks who are involved in office applications which use ODF might like to read up on the proposals and have their say on the future of this feature before a decision is made for you.
I think it is important for ODT to include a good, complete change tracking specification because it would offer all people the ability to collaborate on documents and businesses the change to know the exact extent of modifications made to documents by each party.
Saturday, April 16, 2011
ODF and Generic Change Tracking: part II, styles.
So now abiword can save and load ODF files with improved generic tracked changes to styles. These style changes might be nested, and the window that a style is applied to might shift over revisions. The below video demonstrates the scenario in example 6.4.2 of the generic track changes proposal that is being considered by the Advanced Document Collaboration OASIS ODF Technical subcommittee.
The actual serialization to ODF is along the lines of my proposed output but also using the ac:change stack to avoid unnecessary nesting as has been mentioned that OpenOffice might produce and consume if the generic proposal were to be chosen by the oasis subcommittee.
The actual serialization to ODF is along the lines of my proposed output but also using the ac:change stack to avoid unnecessary nesting as has been mentioned that OpenOffice might produce and consume if the generic proposal were to be chosen by the oasis subcommittee.
ODT Change Tracking part 2: Example 6.4.2 from Ben Martin on Vimeo.
Wednesday, April 13, 2011
Libferris for Fedora 14
Long story short, I decided to update to F14 on the desktop to get easy access to qt4.7 for a project. During that update I rebuilt libferris (of course) and noticed a not so subtle bug in boost 1.44 that comes with f14. See my filed bug 694448 for full details, but basically it stops boost::serialization from reading binary boost archives from files generated with f13's boost. To get around this, the build of ferris includes some more smarts in fallback to the backup text archive.
Lucky for me, in the old days I wanted to copy some *boost files to the maemo platform, and not being 64bit on the target binary archives are not expected to work, so I already had libferris writing plain text too when updates were made. So on f14 things continue to work, and 1.5.4 of libferris onward have more graceful automatic fallbacks for cases where the binary archive fails when it really shouldn't.
You might see this bug if you use semantic smush sets, etagere (tagging), and a few other libferris features with ferris 1.5.3 or less and move to a boost in the 1.42-1.44 range.
Given that F15 should be out soonish, and it seems it will come with boost 1.46, I'm not sure backporting boost::serialization fixes is really on anyone's top ten.
Lucky for me, in the old days I wanted to copy some *boost files to the maemo platform, and not being 64bit on the target binary archives are not expected to work, so I already had libferris writing plain text too when updates were made. So on f14 things continue to work, and 1.5.4 of libferris onward have more graceful automatic fallbacks for cases where the binary archive fails when it really shouldn't.
You might see this bug if you use semantic smush sets, etagere (tagging), and a few other libferris features with ferris 1.5.3 or less and move to a boost in the 1.42-1.44 range.
Given that F15 should be out soonish, and it seems it will come with boost 1.46, I'm not sure backporting boost::serialization fixes is really on anyone's top ten.
Friday, April 8, 2011
ODF and Generic Change Tracking
The OASIS group who are responsible for things like the Open Document Format (ODF) format are throwing around how to improve how change tracking information is to be contained in future versions of ODF. I've hacked some support for the "generic" change tracking proposal into Abiword in a git branch, and Ganesh Paramasivam has been working to make Calligra and KOffice support this too.
I thought a little bit of a look at how documents move between suites was in order. Obviously, these are really trivial changes. The larger use cases screem out for an automated system to test them, so that regressions can be caught and other office suites added over time if they choose to support this method of change tracking.
So, without further (or less) ado, the below video shows a document created in KOffice and bounced through a temporary file to abiword and inspected. Apologies for the delays in the first video, I've sorted that issue of frame dups out for future shows.
In the second video I make some changes in abiword and send those back to KOffice. In the process I found a few little issues which I've committed some updates to the abiword git repo to help with.
These videos where created with recordmydesktop, transcoded with mencode for 720 playback (mainly getting the video codec how vimeo wants to see it), and uploaded with ferriscp foo.avi vimeo://upload.
I thought a little bit of a look at how documents move between suites was in order. Obviously, these are really trivial changes. The larger use cases screem out for an automated system to test them, so that regressions can be caught and other office suites added over time if they choose to support this method of change tracking.
So, without further (or less) ado, the below video shows a document created in KOffice and bounced through a temporary file to abiword and inspected. Apologies for the delays in the first video, I've sorted that issue of frame dups out for future shows.
2011 April 9: KOffice and Abiword with Generic Change Tracking 1of2 from Ben Martin on Vimeo.
In the second video I make some changes in abiword and send those back to KOffice. In the process I found a few little issues which I've committed some updates to the abiword git repo to help with.
2011 April 9: KOffice and Abiword with Generic Change Tracking 2of2 from Ben Martin on Vimeo.
These videos where created with recordmydesktop, transcoded with mencode for 720 playback (mainly getting the video codec how vimeo wants to see it), and uploaded with ferriscp foo.avi vimeo://upload.
Friday, April 1, 2011
Abiword with ODT and Generic Track Changes
I've been hacking support for the proposed generic track changes for ODF into abiword recently. This means that you can generate and store documents with many revisions and see who added/deleted and modified what in which revision over time. Kind of handy for sending your professor the latest design for your perpetual motion machine and being able to see where they think your design might be too optimistic ;)
Anyway, both the branch of abiword and a test suite are up on github to allow anyone to grab it, prod it in the guts, and see how things might operate. Be aware that this is a work in progress right now, and I might commit stuff which is still a work in progress.
The code is at
https://github.com/monkeyiq/odf-2011-track-changes-git-svn
The test suite is at
https://github.com/monkeyiq/odf-2011-track-changes-tests
The following instructions will build abiword from the change tracking code on github. The build will install into /tmp and will not interfere with an abiword which is installed from your Linux distribution's package system. Both abiword builds will be available to you.
$ mkdir tmp
$ cd ./tmp
$ git clone https://github.com/monkeyiq/odf-2011-track-changes-git-svn
$ cd ./odf-2011-track-changes-git-svn
$ ./autogen.sh
$ ./configure --enable-debug \
--enable-collab-backend-service \
--enable-clipart \
--enable-templates \
--prefix=/tmp/abiword-install-odfct \
--enable-plugins="collab"
$ time nice make -j5
$ make install
$ /tmp/abiword-install-odfct/bin/abiword
The download can be done in reasonable time over ADSL, on an Intel Q6600 the make took about 4 minutes. You might like to adjust the -j on the make line to suit your core count. Notice that since everything is installed into /tmp you don't have to run the install as root either. You will get debugging output in the console when using abiword built this way, but that's what you want when running dev code right?
Starting to use change tracking is really easy now too. Though I need to convince somebody who can create clipart to make new icons for revision handling, so the arrow in the below points to the main toolbar icon you want to know about. The icon directly to the right of it will let you select a revision to see from a list.

At first, the additional icons to the right of will not be visible to you as they are only useful when you are using track changes. Each time you click the icon with the arrow pointed at it, abiword will ask to to name a new revision. This makes it nice and simple to create a 5-10 revision test document to play with ODT and Change tracking. Note that abiword can save the change tracking information in it's native abw format as well as ODT. In fact, that is what the core of the test suite linked above does; convert between these formats and make sure that nothing is lost in translations. This way you get to know that abiword can write *and* read back its ODT files without loosing precious information.
Anyway, both the branch of abiword and a test suite are up on github to allow anyone to grab it, prod it in the guts, and see how things might operate. Be aware that this is a work in progress right now, and I might commit stuff which is still a work in progress.
The code is at
https://github.com/monkeyiq/odf-2011-track-changes-git-svn
The test suite is at
https://github.com/monkeyiq/odf-2011-track-changes-tests
The following instructions will build abiword from the change tracking code on github. The build will install into /tmp and will not interfere with an abiword which is installed from your Linux distribution's package system. Both abiword builds will be available to you.
$ mkdir tmp
$ cd ./tmp
$ git clone https://github.com/monkeyiq/odf-2011-track-changes-git-svn
$ cd ./odf-2011-track-changes-git-svn
$ ./autogen.sh
$ ./configure --enable-debug \
--enable-collab-backend-service \
--enable-clipart \
--enable-templates \
--prefix=/tmp/abiword-install-odfct \
--enable-plugins="collab"
$ time nice make -j5
$ make install
$ /tmp/abiword-install-odfct/bin/abiword
The download can be done in reasonable time over ADSL, on an Intel Q6600 the make took about 4 minutes. You might like to adjust the -j on the make line to suit your core count. Notice that since everything is installed into /tmp you don't have to run the install as root either. You will get debugging output in the console when using abiword built this way, but that's what you want when running dev code right?
Starting to use change tracking is really easy now too. Though I need to convince somebody who can create clipart to make new icons for revision handling, so the arrow in the below points to the main toolbar icon you want to know about. The icon directly to the right of it will let you select a revision to see from a list.

At first, the additional icons to the right of will not be visible to you as they are only useful when you are using track changes. Each time you click the icon with the arrow pointed at it, abiword will ask to to name a new revision. This makes it nice and simple to create a 5-10 revision test document to play with ODT and Change tracking. Note that abiword can save the change tracking information in it's native abw format as well as ODT. In fact, that is what the core of the test suite linked above does; convert between these formats and make sure that nothing is lost in translations. This way you get to know that abiword can write *and* read back its ODT files without loosing precious information.
Monday, March 21, 2011
"The desktop" and singularity (also scanning and ferris)
While I normally don't waffle on about higher level touchy feely sorts of things, a recent acquisition of a new scanner prompted my mind to wander through those neurological paths. I think it's fair to say that many folks don't run just one, but many desktops these days. And no, this is not about KDE vs GNOME vs emacs as your desktop, but rather that a whole KDE4 session is happening on another (virtual) machine which is brought across to the normal "main" desktop.
This gives me many apps running on many machines and also proxy X sessions and X-VNC sessions in windows (which normally have an embedded panel et al). A take away idea I had here was why when I have Abiword in the menus is there not an offer to run it on server-Y which I have an ssh key for instead of the local host? Or to bring xpra into the mix there as well. Sure, this is likely not an idea that folks who only own a single machine or laptop will like, but that demographic is surely shrinking fast. Add in nepomuk for tracking this and if I run amarok on furryshark7 most of the time then surely that can become the default host for it's icon rather than localhost.
The scanner idea was simple, a USB scanner, a USB hub to attach it to the host through and a handful of USB sticks. Each stick has a profile (username, colour, dpi etc) and to scan just put the document into the scanner and drop in the usb stick for a moment. Then the host knows the parameters and can put the file into a user specific directory on an intranet share so only the document holder can actually see the scanned version. Privacy and convenience, a rare thing!
Of course now that I have a scanner which doesn't suck, libferris will be getting sane support so I can "cp" documents right from the scanner to the filesystem or web...
cp sane://my-scanner-model/600dpi/colour/adf1.jpg flickr://me/upload
And the reason files are numbered is so a single copy can grab 30 documents from the ADF with a normal copy syntax. In practice, adf2 and adf1 both just scan the next piece of physical paper and give you it encoded in an appropriate manner (jpg for example). The fun part will be smoothing over a paper jam at document 7 of 16.
sync && umount blog://
This gives me many apps running on many machines and also proxy X sessions and X-VNC sessions in windows (which normally have an embedded panel et al). A take away idea I had here was why when I have Abiword in the menus is there not an offer to run it on server-Y which I have an ssh key for instead of the local host? Or to bring xpra into the mix there as well. Sure, this is likely not an idea that folks who only own a single machine or laptop will like, but that demographic is surely shrinking fast. Add in nepomuk for tracking this and if I run amarok on furryshark7 most of the time then surely that can become the default host for it's icon rather than localhost.
The scanner idea was simple, a USB scanner, a USB hub to attach it to the host through and a handful of USB sticks. Each stick has a profile (username, colour, dpi etc) and to scan just put the document into the scanner and drop in the usb stick for a moment. Then the host knows the parameters and can put the file into a user specific directory on an intranet share so only the document holder can actually see the scanned version. Privacy and convenience, a rare thing!
Of course now that I have a scanner which doesn't suck, libferris will be getting sane support so I can "cp" documents right from the scanner to the filesystem or web...
cp sane://my-scanner-model/600dpi/colour/adf1.jpg flickr://me/upload
And the reason files are numbered is so a single copy can grab 30 documents from the ADF with a normal copy syntax. In practice, adf2 and adf1 both just scan the next piece of physical paper and give you it encoded in an appropriate manner (jpg for example). The fun part will be smoothing over a paper jam at document 7 of 16.
sync && umount blog://
Thursday, January 20, 2011
From Canon CR2 Raw files to the Web
A potentially interesting artefact of me playing around with a Canon DSLR is that libferris now has some initial support for CR2 "raw" files. Complements of course go to the dcraw library and tools for the heavy lifting. The upshot is that ferriscp ~/cam/foo.CR2 flickr://me/upload now works as expected. Once I update my maemo build, this should also let me use an n900 with 3G to upload from RAW while on the move.
I need to include stuff for ICC profiles and the like but at least the Web services get what they expect and everything runs smoothly, and it will for you too next release (TM). I really should look into mounting the kipi plugins as a filesystem sometime, they offer some awesome Web import/export functionality, ripe for a filesystem I tell's ya.
I still need to add "rgba-32bpp" metadata support for CR2 files. As you can imagine from the name, if you read this metadata for a jpeg, png or other supported image file, libferris decodes the image to 32 bit RGBA byte values for you. It might also be interesting to create another "file as filesystem" design where a bunch of virtual files are offered to see the small thumbnail, the roughly 1080p sized thumbnail or the ICC corrected rendering of the CR2 and others. Such virtual files are really handy for drag and drop to other filesystems ;)
I might hunt around for some Nikon raw files to add support for those too at some point. Though there is nothing like having a camera generating files to make you want to make your software support those files.
I need to include stuff for ICC profiles and the like but at least the Web services get what they expect and everything runs smoothly, and it will for you too next release (TM). I really should look into mounting the kipi plugins as a filesystem sometime, they offer some awesome Web import/export functionality, ripe for a filesystem I tell's ya.
I still need to add "rgba-32bpp" metadata support for CR2 files. As you can imagine from the name, if you read this metadata for a jpeg, png or other supported image file, libferris decodes the image to 32 bit RGBA byte values for you. It might also be interesting to create another "file as filesystem" design where a bunch of virtual files are offered to see the small thumbnail, the roughly 1080p sized thumbnail or the ICC corrected rendering of the CR2 and others. Such virtual files are really handy for drag and drop to other filesystems ;)
I might hunt around for some Nikon raw files to add support for those too at some point. Though there is nothing like having a camera generating files to make you want to make your software support those files.
Monday, January 3, 2011
Talking: RDF and Office Documents
I should be giving a talk about RDF and ODF next saturday (8th jan) at Humbug in Brissie. The challenge is that work is reasonably embryonic in the area, but there are already useful things that can be done like drag and drop of contact and calendar information to/from ODF files. As its a technical meetup I'll be going into the range stuff and how to link semantics to document text. Sorry for the brief post, but hopefully you see it and come along if you want to bounce richer information around in ODF files between OpenOffice, Calligra, and Abiword.
Subscribe to:
Posts (Atom)